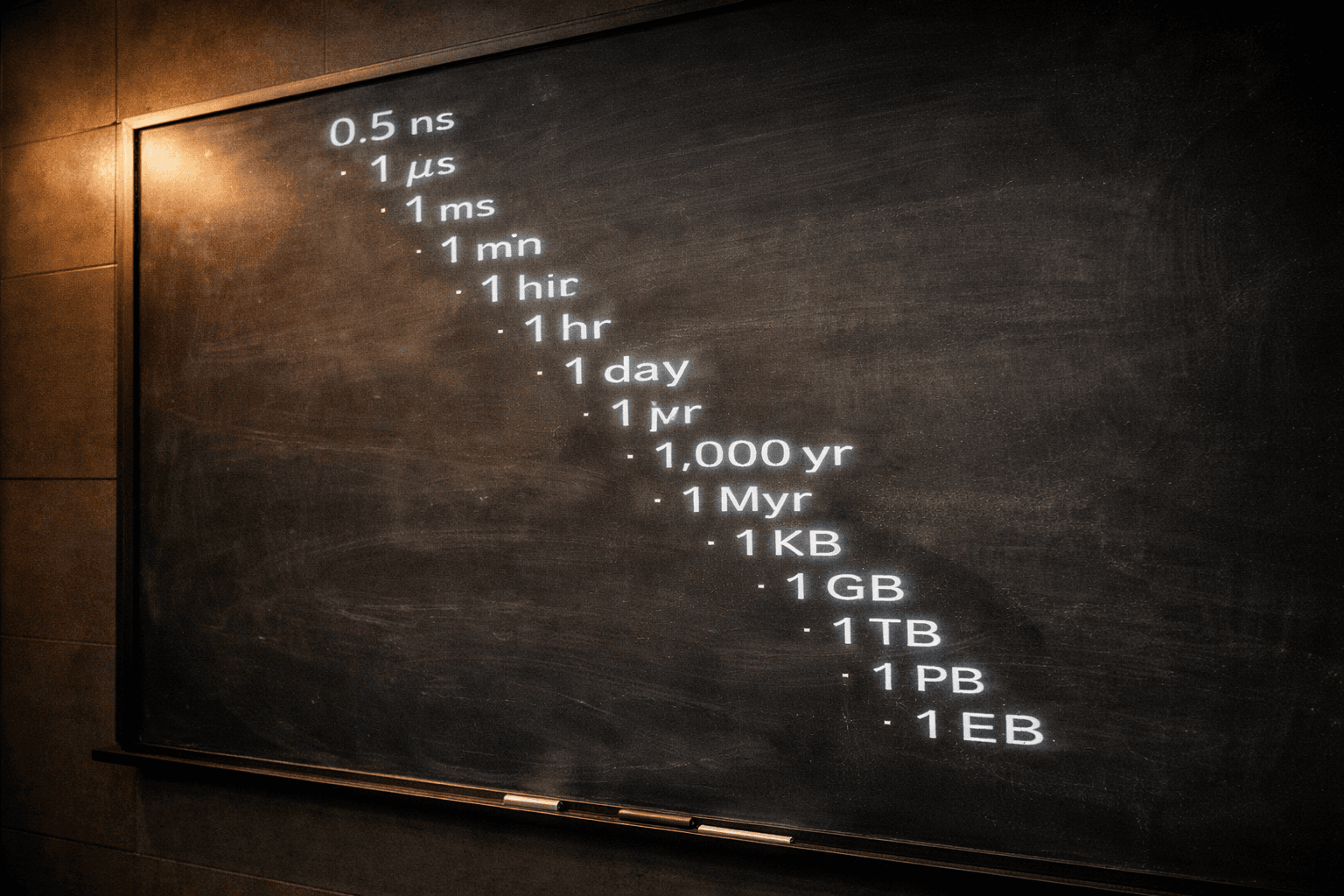This is Part 5 of the solution architecture series. Part 1 covered the five forces. Part 2 covered resilience patterns. Part 3 covered shipping discipline. Part 4 walked through the scaling journey from 50 rps to 500,000 — with the actual configs, queries, and decisions.
Part 4 ended with a promise: the specific subsystems that hold the architecture together at scale. The load balancer configurations. The CDN edge caching strategies. The exact monitoring setup that tells you when the next bottleneck is approaching before it arrives.
Here they are. Same healthcare claims system. Same team. Same philosophy: measure first, intervene with the smallest change that buys time.
Load Balancing at 500K rps
At 50 rps, a load balancer is a proxy. At 500K rps, it is a traffic engineering system — and getting it wrong means either dropping requests or routing them to instances that are already drowning.
The Setup
We ran two layers of load balancing:
Layer 1 — Global (Global Accelerator + CloudFront): We started with Route 53 latency-based routing but moved to AWS Global Accelerator for the API traffic — anycast IPs, instant failover (no DNS TTL delay), and TCP termination at the nearest AWS edge. CloudFront still handles the cacheable content. US users hit us-east, EU users hit eu-west, APAC hit ap-southeast. If a region's health check fails, Global Accelerator reroutes in seconds — not the 30-60 seconds DNS-based failover takes.
Layer 2 — Regional (ALB for external, Envoy for internal): External API traffic hits an ALB per region — we need path-based routing and HTTP-level health checks. Internal service-to-service traffic runs through Envoy sidecars with mTLS. In healthcare, every hop between services carries PHI — mutual TLS isn't optional, it's HIPAA. Envoy gives us L7 routing, automatic retries, circuit breaking, and observability on internal traffic that a raw NLB can't provide.
The Config That Matters
# ALB Target Group settings that took us months to get right
# Deregistration delay: how long ALB waits before removing
# a draining instance. Default is 300s. We use 30s.
# Why: during deployments, 300s means the old pods stay in
# rotation for 5 minutes after they've stopped accepting new
# connections. At 500K rps, that's millions of requests
# hitting instances that are shutting down.
deregistration_delay = 30
# Health check interval and thresholds
health_check_interval = 5 # seconds (default: 30)
healthy_threshold = 2 # consecutive successes to mark healthy
unhealthy_threshold = 2 # consecutive failures to mark unhealthy
# Health check path: not "/" — a dedicated endpoint that checks
# downstream dependencies
health_check_path = "/health/deep"
# Idle timeout: how long to keep connections open
idle_timeout = 60 # seconds
# Stickiness: OFF. Stateless services don't need it.
# Stickiness at this scale creates hotspots.
stickiness = false
The /health/deep Endpoint
This is the single most important URL in the system. It doesn't just return 200. It checks:
# Simplified version of our deep health check
def health_deep():
checks = {
"database": check_db_connection(), # Can we reach the shard?
"redis": check_redis_ping(), # Is cache responding?
"kafka": check_kafka_producer(), # Can we produce messages?
"disk": check_disk_space() > 10, # >10% free?
"memory": check_memory() < 90, # <90% used?
}
if all(checks.values()):
return {"status": "healthy"}, 200
else:
failed = [k for k, v in checks.items() if not v]
return {"status": "degraded", "failed": failed}, 503When /health/deep returns 503, the ALB stops sending new requests to that instance within 10 seconds (2 checks × 5-second interval). The instance stays alive — it finishes processing in-flight requests during the 30-second deregistration window — but new traffic goes elsewhere. No dropped connections. No error spikes. The system routes around the problem before users notice.
The shallow health check trap. If your health endpoint just returns 200 without checking dependencies, your load balancer will keep sending traffic to an instance that can't reach its database. The instance looks healthy to the ALB but returns 500s to every request. We learned this the hard way during a Redis failover — the ALB kept routing traffic to pods that were "healthy" but couldn't cache anything, which sent 500K rps directly to the database. It went down in ninety seconds.
ALB vs Envoy: When to Use Which
| ALB (External) | Envoy Sidecar (Internal) | |
|---|---|---|
| Layer | 7 (HTTP) | 7 (HTTP/gRPC) |
| Use case | Public API, path-based routing | Service-to-service, mTLS, observability |
| Latency added | ~1-3ms | ~0.3-0.5ms (sidecar hop) |
| Security | TLS termination | Mutual TLS — every hop encrypted |
| Observability | Access logs, CloudWatch | Per-request metrics, distributed traces, L7 visibility |
| Retries/Circuit breaking | Basic (target group level) | Fine-grained, per-route, with backoff |
The public API sits behind ALB — we need path-based routing (/v1/claims → claims service, /v1/auth → auth service) and HTTP-level health checks. Internal service-to-service calls flow through Envoy sidecars — gRPC traffic with automatic mTLS, L7 retries, and per-request telemetry that feeds directly into our tracing pipeline.
The mistake teams made in 2022 was putting everything behind ALB because it was easier to configure. The mistake teams make in 2026 is deploying a full Istio service mesh for five services. We run Envoy sidecars without the Istio control plane — the data plane gives us what we need (mTLS, retries, observability) without the operational overhead of managing Istio's CRDs. The internal traffic between our services — eligibility checks, claim validation, authorization lookups — makes 2-3 hops per external request. Envoy on internal paths with mTLS gave us both the security HIPAA demands and the latency savings we needed.
Connection Draining: The Deploy That Doesn't Drop Requests
At 500K rps, you deploy multiple times a day. Every deploy replaces pods. Every pod replacement means active connections need to finish gracefully.
The sequence:
- Kubernetes sends SIGTERM to the pod and removes it from Service endpoints (async)
- The
preStophook fires —sleep 5— giving the ALB time to notice the endpoint removal - ALB health check detects the pod is deregistering and starts the deregistration delay (30s)
- During these 30s, ALB stops sending new requests but allows in-flight requests to complete
- Pod continues processing in-flight requests throughout
- After deregistration completes, pod's
terminationGracePeriodSeconds(45s) provides the final buffer - Pod shuts down gracefully
The critical number: terminationGracePeriodSeconds must be greater than deregistration_delay. If the pod dies before the ALB finishes draining, connections drop. We set the pod at 45s and the ALB at 30s — a 15-second buffer that has never failed.
# Kubernetes deployment snippet
spec:
terminationGracePeriodSeconds: 45
containers:
- name: claims-api
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 5"]
# The 5-second preStop sleep gives the ALB time to
# register the deregistration before the pod starts
# refusing connections. Without it, there's a race
# condition where the pod stops accepting before the
# ALB knows it should stop sending.Before we tuned this, a routine deploy during peak hours dropped roughly 40,000 requests in 90 seconds. The pod terminated in 30 seconds (default terminationGracePeriodSeconds), but the ALB was still draining for 300 seconds (default deregistration_delay). The ALB kept sending traffic to a pod that no longer existed. The fix took four lines of YAML and saved us a weekly incident.
CDN Edge Caching
Healthcare claims data is sensitive — you can't cache a patient's authorization status at a CDN edge. But not everything in the system is sensitive. The parts that aren't sensitive account for a surprising amount of traffic.
CDNs are not just for static websites. Most enterprise architects skip CDN entirely because "our app is dynamic." Every enterprise application has a static spine — auth validation, config fetches, schema lookups, reference data, health checks — running at 10-100x the volume of the actual business logic. CDNs eat that spine. Beyond caching, they solve three enterprise problems: edge auth rejection (invalid requests never reach your origin), API response caching (even a 60-second TTL on lookup tables absorbs enormous load), and DDoS/rate limiting (volumetric attacks get absorbed before they touch your VPC). If your enterprise API serves more than 1,000 rps, a CDN is not optional — it is infrastructure.
What We Cache at the Edge
| Content | TTL | Cache-Control | Why |
|---|---|---|---|
| API schema / OpenAPI docs | 24 hours | public, max-age=86400 | Changes once per release |
| Payer rule sets | 1 hour | public, max-age=3600, stale-while-revalidate=300 | Updated daily, stale is acceptable |
| Code lookup tables (ICD-10, CPT) | 12 hours | public, max-age=43200 | Changes quarterly |
| Static assets (JS, CSS, images) | 1 year | public, max-age=31536000, immutable | Content-hashed filenames |
| Eligibility check results | NEVER | private, no-store | Patient-specific, HIPAA |
| Claim status | NEVER | private, no-store | Patient-specific, HIPAA |
The code lookup tables alone — ICD-10 has 72,000+ codes, CPT has 10,000+ — represent a significant chunk of API calls. Every claim validation hits these tables. Caching them at the edge eliminated roughly 35% of requests that would have hit our origin servers. At 500K rps, that's 175K requests per second that never touch our infrastructure.
Edge Compute: JWT Validation at the Edge
At 500K rps, every request that reaches your origin costs compute. If 15-20% of those requests are unauthenticated or carry expired tokens, you're spending origin capacity rejecting garbage.
We use CloudFront Functions to validate JWT signatures at the edge — before the request ever reaches the ALB. The function checks token expiry, validates the signature against a cached public key, and returns 401 directly from the edge location if the token is invalid. For a healthcare system, this means PHI-bearing requests only reach the origin if the caller is authenticated. At our scale, this filters roughly 80,000 invalid requests per second at the edge — requests that used to consume ALB connections and pod CPU just to return a 401.
// CloudFront Function — JWT validation (simplified)
function handler(event) {
var request = event.request;
var token = request.headers.authorization?.value?.replace('Bearer ', '');
if (!token || !isValidJwt(token)) {
return {
statusCode: 401,
body: { message: 'Unauthorized' }
};
}
return request; // Pass to origin
}CloudFront Functions run in under 1ms, cost a fraction of Lambda@Edge, and execute at all 400+ edge locations. For heavier logic — request transformation, A/B routing, geo-based access control — we use Lambda@Edge at the regional edge caches. But for auth validation, CloudFront Functions are the right tool.
Origin Shield
This is the CDN feature most teams don't know about. Without origin shield, each edge location (CloudFront has 400+) independently fetches from your origin when its cache expires. If you have a popular resource cached at 100 edge locations and the TTL expires, you get 100 simultaneous requests to your origin.
With origin shield, all edge locations funnel through a single regional cache first. Cache miss at the edge → check origin shield → only if origin shield also misses → hit the actual origin. One origin request instead of 100.
# CloudFront distribution config
Origin Shield: Enabled
Origin Shield Region: us-east-1 # Same region as our primary
# Result: origin requests dropped 94% on cache expiry events
We enabled origin shield after a cache invalidation (deploying updated payer rule sets) caused a thundering herd that spiked origin CPU to 97%. The fix was one checkbox.
Cache Invalidation: The Hard Problem
"There are only two hard things in Computer Science: cache invalidation and naming things." We solved naming things by not trying. Cache invalidation we solved with a pattern:
Content-hashed static assets: The filename changes when the content changes. app.a3f8b2.js never needs invalidating — when we deploy, the HTML references a new hash, and the old file quietly expires.
Versioned API responses: Payer rule sets include a version header. The cache key includes the version. When rules update, the version increments, and the old cache entries expire naturally — no explicit invalidation needed.
Manual invalidation as a last resort: We invalidate the CDN cache maybe twice a quarter, always for "we published wrong data and need to fix it now" situations. The pattern is: fix the origin data first, invalidate the CDN path second, verify at three edge locations third. Never invalidate without fixing the origin — you'll just re-cache the same bad data.
The Monitoring Setup
At 50 rps, you can tail a log file. At 500K rps, you need a system that thinks for you — surfacing the signal before you know to look for it.
The Stack: OpenTelemetry as the Backbone
In 2022, our observability stack was Prometheus for metrics, structured JSON logs shipped to Loki, and Jaeger for traces — three separate pipelines, three separate collection agents, three separate query interfaces. By 2024, we consolidated everything onto OpenTelemetry. One SDK. One collector. Traces, metrics, and logs unified under a single correlation model.
This matters at 500K rps because debugging a slow claim requires jumping from a Grafana dashboard (high p99 on shard-03) to a trace (this specific request spent 340ms in a DB query) to a log line (the query hit a missing index on the payer_rules table) to a continuous profile (the claims-validation service is spending 40% of CPU in JSON deserialization). With OTel, the trace_id connects all four. Without it, you're copy-pasting IDs between three tools at 3am.
The Three Layers
Layer 1 — Infrastructure metrics (CloudWatch + Prometheus): CPU, memory, disk, network across every instance. These are the vital signs. You don't diagnose with them, but you know something is wrong.
Layer 2 — Application metrics (OTel → Prometheus + Grafana): Request rate, error rate, latency percentiles (p50, p95, p99), queue depth, cache hit ratio, database connection pool utilization. These are the diagnostics. They tell you what is wrong. OTel auto-instrumentation gives us per-endpoint latency breakdowns without touching application code.
Layer 3 — Business metrics (Custom dashboards): Claims processed per minute, average adjudication time, denial rate, dollar value in pipeline, cost per claim processed. These are the outcomes. They tell you if it matters — and what it costs.
Most teams build layer 1 and stop. Some build layers 1 and 2. Almost nobody builds layer 3 — which means they can tell you the database is slow but not that claims are backing up and providers aren't getting paid. The cost-per-claim metric is the one that connects engineering to business: if your infrastructure cost is $180K/month and you process 30 million claims, your cost per claim is $0.006. When that number drifts above $0.008, something is wrong — and FinOps is no longer a dashboard, it's an engineering priority.
The Alerts That Actually Wake People Up
We have exactly 14 alerts that page the on-call engineer. Not 140. Not 40. Fourteen. Every one of them means "a human must act within 15 minutes or users are affected."
| Alert | Threshold | Why This Number |
|---|---|---|
| Error rate > 1% for 3 min | 1% of 500K rps = 5,000 errors/min | Below 1% is noise — transient failures, client errors |
| p99 latency > 500ms for 5 min | SLA is 200ms p50, 500ms p99 | p99 breaching means tail latency is affecting real users |
| Queue depth > 10,000 for 5 min | Normal is 200-500 | 10K means consumers are falling behind |
| Cache hit ratio < 80% for 10 min | Normal is 94-96% | Below 80% means origin is taking traffic it shouldn't |
| Database connection pool > 85% | Pool size is 100 per shard | At 85%, the next traffic spike saturates the pool |
| Disk space < 15% on any node | — | Logs fill disks. Disks fill fast at 500K rps |
| Pod restart count > 3 in 10 min | — | OOMKills or crash loops |
| Certificate expiry < 14 days | — | The outage that's 100% preventable and 100% embarrassing |
The remaining 6 are variations — per-region error rates, Kafka consumer lag, cross-region replication delay, health check failure count, deployment rollback trigger, and cost anomaly (spend > 120% of trailing 7-day average).
The alert that saved us the most money isn't in the table above. It's the cost anomaly alert. A misconfigured auto-scaler once spun up 200 extra instances on a Saturday night. Nobody noticed the performance change — the system ran fine with 200 extra instances. The cost alert fired on Sunday morning: "Spend is 340% of trailing average." We caught it before Monday. Without it, that misconfiguration would have cost $40,000 before anyone opened a dashboard.
The Dashboard That Matters
Every engineer on the team has one dashboard bookmarked. Not the infrastructure dashboard. Not the deployment dashboard. This one:
The Golden Signals Dashboard — four panels:
- Request rate — traffic volume, per service, per region. The heartbeat.
- Error rate — 5xx and 4xx, per service, per endpoint. The pulse.
- Latency — p50, p95, p99, per service. The blood pressure.
- Saturation — CPU, memory, connection pool, queue depth. The capacity remaining.
These four numbers — rate, errors, latency, saturation — are from Google's SRE book. They're not original. But having them in four panels on one screen, refreshing every 10 seconds, with the last 24 hours visible — that is the difference between "we noticed the degradation at 3am" and "we noticed it at 3:15am when the page fired."
At 500K rps, 15 minutes of unnoticed degradation is 450 million requests. At our error rates during incidents, that's 4.5 million failed requests — 4.5 million claims that didn't process, 4.5 million healthcare transactions that a provider is waiting on. The golden signals dashboard isn't a nice-to-have. It's the reason the on-call engineer sleeps.
The Observability Layers You Didn't Know You Needed
eBPF for network visibility: On the internal traffic path — Envoy sidecars talking to each other across pods — we run Cilium with Hubble for eBPF-based network observability. Zero instrumentation. No code changes. Hubble shows us every TCP connection, every DNS resolution, every HTTP request between services, with latency and error rates — at the kernel level. When a service-to-service call is slow, Hubble tells us whether the delay is in the application, the network, or the sidecar — before we open a single dashboard. For the internal NLB paths where we don't have L7 visibility from the load balancer, eBPF is how we see.
Continuous profiling: At 500K rps, a function that takes 2ms instead of 0.5ms doesn't show up in logs or traces. It shows up in your cloud bill. We run Grafana Pyroscope for continuous CPU and memory profiling across all services. Always on, sampled, negligible overhead. When the claims-validation service started consuming 30% more CPU after a routine deploy, the profiler showed that a new JSON schema validation library was 4x slower at deserialization than the one it replaced. The trace said "47ms total." The profiler said "18ms of that 47ms is in schema.validate()." That's a level of insight that metrics and traces alone will never give you.
Predictive scaling: We use AWS predictive auto-scaling alongside reactive auto-scaling. The system learns traffic patterns — Monday morning claim submission surges, month-end processing spikes, open enrollment floods in November — and pre-scales 15-30 minutes before the traffic arrives. Reactive scaling alone at 500K rps means the surge hits before the new pods are warm. Predictive scaling means the pods are already there, health-checked and in rotation, when the first wave lands.
Structured Logging at Scale
At 500K rps, each request generates 3-5 log lines. That's 1.5-2.5 million log lines per second. You cannot search them with grep. You cannot afford to store all of them forever.
Our logging strategy:
# Log levels and retention
ERROR → stored 90 days, indexed, searchable, alerts
WARN → stored 30 days, indexed, searchable
INFO → stored 7 days, sampled at 10%
DEBUG → production: OFF (enabled per-pod for troubleshooting)
The 10% sampling on INFO is the key decision. At full volume, INFO logs cost us $40,000/month in ingestion, storage, and indexing (we self-host on OpenSearch with reserved instances — managed services like Datadog would be 3-4x that). At 10%, they cost $4,000/month and still give us enough signal to diagnose any issue. The trick: every sampled log line includes a trace_id. When we need the full picture for a specific request, we can pull all log lines for that trace from the unsampled stream (retained in S3 for 48 hours before deletion).
{
"timestamp": "2025-11-14T03:22:41.887Z",
"level": "INFO",
"service": "claims-api",
"trace_id": "abc-123-def-456",
"span_id": "span-789",
"method": "POST",
"path": "/v1/claims",
"status": 201,
"duration_ms": 47,
"shard": "shard-03",
"region": "us-east-1",
"payer_id": "BCBS-TX",
"claim_type": "professional"
}Every log line is JSON. Every log line has a trace ID. Every log line includes the business context (payer_id, claim_type) alongside the technical context (shard, region, duration_ms). When the on-call engineer is debugging at 3am, they're not just looking for slow requests — they're looking for slow requests for a specific payer, on a specific shard, in a specific region. The business context in the log line is what turns a 45-minute investigation into a 5-minute one.
What Holds and What Breaks
After five parts, a pattern should be visible. The subsystems that hold at scale are never the clever ones. They're the ones where someone spent an afternoon tuning four numbers — a deregistration delay, a health check interval, a cache TTL, an alert threshold — and those four numbers absorbed a million requests per second worth of chaos without anyone noticing.
The subsystems that break are the ones where someone said "we'll tune that later" and later never came. Default timeouts. Shallow health checks. Alerts set to thresholds that fire twelve times a day until everyone ignores them. Logs at full volume with no sampling, costing a fortune and drowning signal in noise.
At scale, the system that survives is not the one with the best architecture diagram. It is the one where someone cared enough to set the deregistration delay to 30 seconds instead of 300 — and wrote a comment explaining why.
The healthcare claims system from Part 4 is still running. It still serves 500K rps. The load balancer configs have barely changed in two years. The CDN cache strategy has been the same since we enabled origin shield. The 14 alerts are the same 14 alerts. The golden signals dashboard is the same four panels.
The boring subsystems — the ones nobody writes conference talks about — are the ones that let the team sleep through the night. And sleeping through the night, at 500K rps, with healthcare claims flowing through the pipes — that's the real architecture.
The series continues. The next piece is the reference card — the latency numbers, availability math, cloud economics, and estimation framework that every architect should carry into a design review. After that, a system design capstone that puts everything from the series together.